
Caylent Catalysts™
Disaster Recovery Strategy
Determine the disaster recovery (DR) strategy best suited to protect your workloads on AWS, tailored to your budgets and recovery targets.
Discover how you can leverage the AWS Well-Architected Framework to build the most secure, high-performing, resilient, and efficient infrastructure possible for your applications.
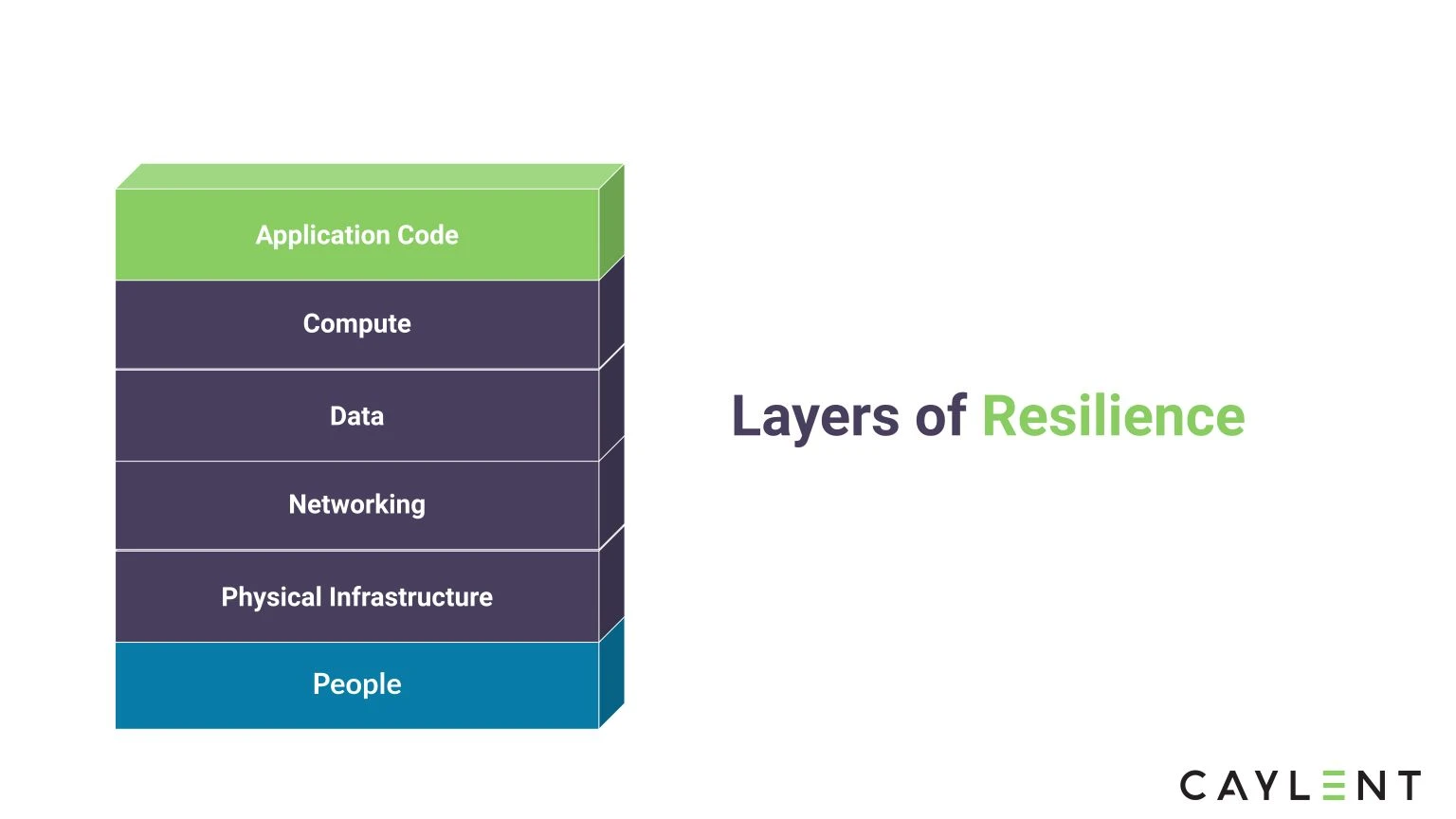
Disaster Recovery (DR) in Amazon Web Services (AWS) is a component that spans a few of the six pillars of the AWS Well-Architected Framework. The AWS Well-Architected Framework provides guidance to organizations to build the most secure, high-performing, resilient, and efficient infrastructure possible for their applications. DR and resiliency align, primarily, with the reliability pillar of the Well-Architected Framework. This pillar states that reliability requires that your workload be aware of failures as they occur and take action to avoid impact on availability. Workloads must be able to both withstand failures and automatically repair issues. Although automatically repairing issues is an incredible feature, not all organizations have such stringent requirements. Disaster Recovery as defined by Gartner “the methods and procedures for returning a data center to full operation after a catastrophic interruption”. DR is explored here with the ability to recover from failure or catastrophic interruption. This article explores how DR aligns with the AWS Well-Architected Framework, how business processes shape a sound DR strategy, and how Caylent can lead your organization to success when planning for DR.
Disaster recovery is a critical element of an organization’s business continuity plan as it allows organizations to continue operating critical workloads following an unplanned interruption. A sound disaster recovery strategy can enable organizations to remain profitable and continuously provide value to their customers. Additionally, disaster recovery strategies are often an essential requirement for some organizations that allow them to meet specific regulatory compliance standards, such as the National Institute of Standards and Technology Cybersecurity Framework (NIST-CSF).
Accessible AWS Cloud Map Diagram
DR strategies for an organization should start with people first and then the technical processes. The goal in planning for DR should be, if an outage does occur, to successfully mitigate the degradation of downstream processes that might include customer or user access to a system. Business architecture is the driver of the overall resiliency footprint of an organization. The Open Group’s Architectural Framework (TOGAF) suggests business architecture defines the business strategy, governance, organization, and key business processes. Business architecture should be the predecessor for architecture in any other domain, including data, applications, and technology. Non-functional requirements (NFR) such as the location of users, security and compliance of an application, and availability are critical drivers to architecting for DR from a business architecture lens. By identifying elements that are absolutely critical to the success of a business, it will be easier to architect the technical components for disaster recovery.
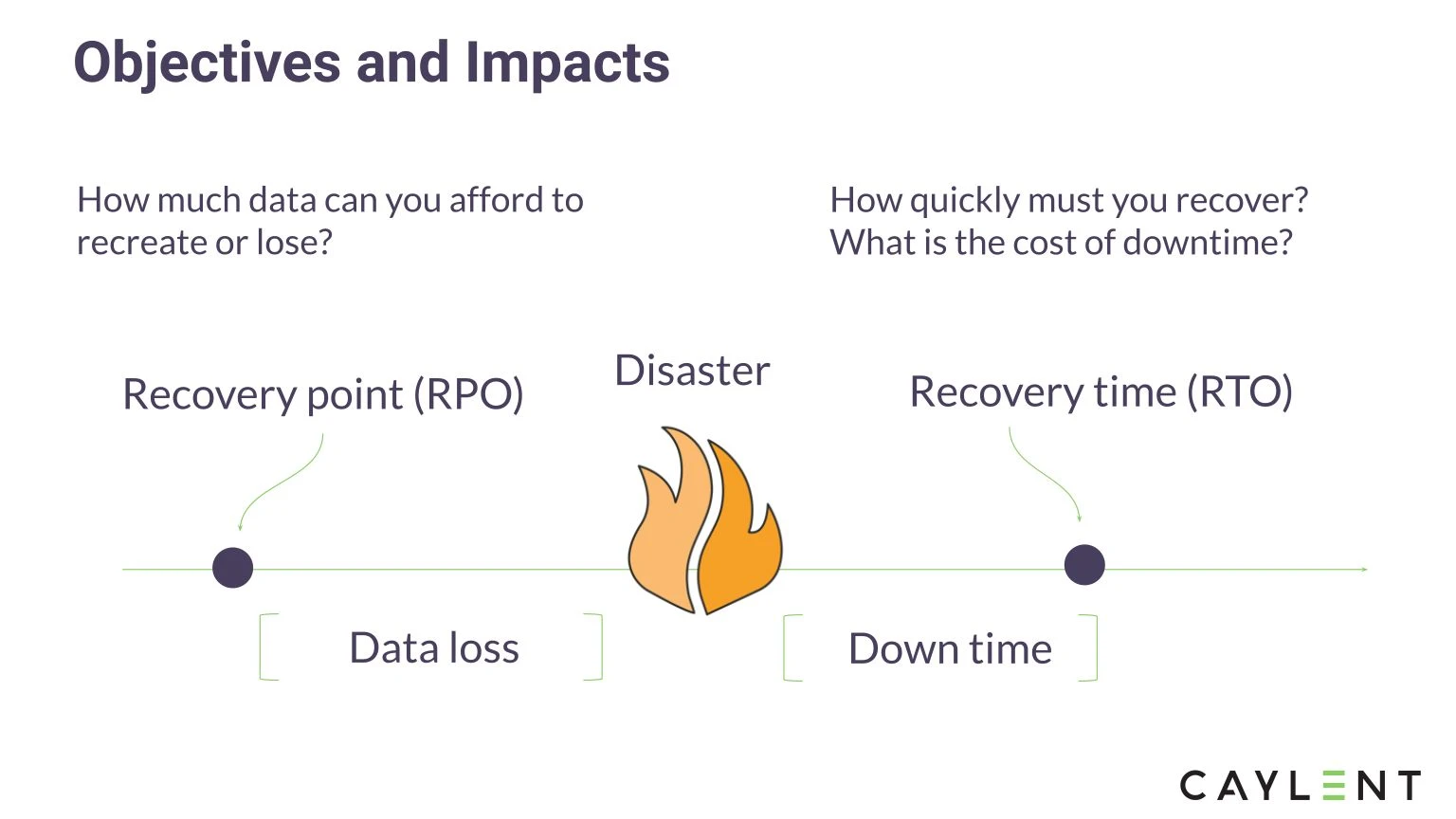
When architecting for DR, there are a couple of metrics to bear in mind that can have downstream impacts to users and customers. Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two metrics that will drive an organization’s DR strategy. RTO is the maximum amount of time that is acceptable for a system to be offline before restoration. RPO is the maximum acceptable time since the last data recovery point. This determines how much data loss is acceptable during an outage.
Perhaps the only confusing implementation detail of Service Connect is that you can configure Discovery Names, Client Aliases, and Port Names for the resolution of a specific endpoint within a service, and there is a light hierarchy in how these values get rolled up into an AWS Cloud Map namespace. You can read a detailed description within the Amazon ECS Develop Guide, but they essentially work like this:
Each endpoint is an exposition of a port hosted within your Amazon ECS service, which is provided a port name. Atop these named ports, you may define a Client Alias that represents the service within AWS Cloud Map (that then points back to the named port). An optional Discovery Name can be layered atop the Client Alias, but if none is provided, the Client Alias is used for this value also.
For organizations such as health care providers or financial providers, where every transaction can either save a life or make or save millions of dollars, a DR strategy should be a non-negotiable.
AWS has poignantly presented several DR strategies to meet varying customers’ requirements. These strategies range from several hours RTO/RPO (Backup and Restore) to those that can take seconds (Active-Active.) When working with a consulting partner such as Caylent, our goal is to ensure your organization is successful in whatever strategy is appropriate for your team and workload. For customers who have just begun their journey to DR, the Caylent DR Catalyst is an exceptional opportunity to work with our experts and to plan and prepare for your DR implementation.
The Disaster Recovery Strategy Caylent Catalyst is a 2-week engagement that allows your team to go on a deep dive for your architectural requirements to support DR. This includes business architecture and NFRs such as regional availability, RTO/RPO, latency, regulatory compliance requirements, and more. Additionally, we provide our expertise around best practices to enhance a previously existing AWS footprint with tools such as Infrastructure as Code to allow for a portable and repeatable way to redeploy an architecture. Caylent cloud architects and engineers will actively engage with your organization to identify opportunities for cost savings and technical opportunities as it relates to DR planning.
DR Planning should be an activity that is very intentional in its outcome and desired state. The Caylent team will work closely with your organization to meet specific goals while planning for DR such as organizational-specific regulatory compliances, and operational excellence. The Caylent team will also review DR testing strategies to mimic outages. This exercise allows your organization to glean immediate value in understanding how to architect for resilience and preparing your organization for business continuity from this engagement.
With our consideration of AWS’ Well-Architected Framework, your organization’s business and technical architecture requirements, in addition to our years of experience and expertise in guiding customers to success and preparing for disaster before disaster strikes, your organization will be primed to continuously provide value to your end-users and customers when a disaster does strike. As AWS Chief Technology Officer Werner Vogels stated,”Everything fails all of the time”. Let Caylent be the organization that helps you plan for and mitigate failure.

Randall Hunt, Chief Technology Officer at Caylent, is a technology leader, investor, and hands-on-keyboard coder based in Los Angeles, CA. Previously, Randall led software and developer relations teams at Facebook, SpaceX, AWS, MongoDB, and NASA. Randall spends most of his time listening to customers, building demos, writing blog posts, and mentoring junior engineers. Python and C++ are his favorite programming languages, but he begrudgingly admits that Javascript rules the world. Outside of work, Randall loves to read science fiction, advise startups, travel, and ski.
View Randall's articles

Explore how ACGR in CxPortal extends Amazon Connect Global Resiliency by giving contact center operations teams a centralized, playbook-driven way to execute, manage, and monitor regional failover and recovery, reducing downtime and accelerating response during service disruptions.

A global education publisher partnered with Caylent to strengthen security controls for sensitive data and achieve compliance with StateRAMP Moderate requirements, enabling them to better serve university clients with increased confidence and trust.

Discover how we helped a public health data provider migrate to AWS to drive sales growth and strengthen regulatory compliance.