
Caylent Services
Data Modernization & Analytics
From implementing data lakes and migrating off commercial databases to optimizing data flows between systems, turn your data into insights with AWS cloud native data services.
Learn how to build foundations for data lakes that can drive your self-service analytics & improve time to market, efficiency, and cost effectiveness.
According to Gartner research, “the average financial impact of poor data quality on organizations is $9.7 million per year.” In this article, I will discuss how to build the foundation for a governed data quality data lake that can drive your self-service analytics, improve your time to market, improve efficiency, and reduce overall costs.
Gold miners in Alaska continuously run massive amounts of raw dirt through a processing plant in order to extract a comparatively small amount of gold flecks and, with luck, some nice-sized nuggets. Similarly, knowledge workers have to spend the majority of their time processing vast amounts of raw data to actually extract valuable insights.
Combining, cleaning, sorting, merging, scrubbing, and fixing data for use is a laborious task involving quite a bit of data engineering rigor.
A little data science humor: A data scientist spends 95% of their time dealing with problems with the data and the other 5% complaining about how much time they spend dealing with data problems!
Just as a dump truck full of unprocessed “paydirt” holds only the potential of valuable gold, data at rest also only has potential value. The goal is to monetize this potential value by creating a kind of processing plant or refinery for the data. Ideally, companies should make the process as efficient, automated, and repeatable as possible. Such a refinery will ingest all types of raw data and, more importantly, process it through stages of increasing data quality. The idea is to continuously produce fresh, quality data ready for consumption.
Several basic patterns exist for setting up a data lake to enable efficient data flow and thereby enable the refinery. A data lake should address data quality, implement governance, and enable self-service exploratory analysis for trusted datasets. These trusted datasets allow analysts and data scientists to expertly refine and monetize the data and produce valuable insights. Trusted datasets also provide a single version of the truth.
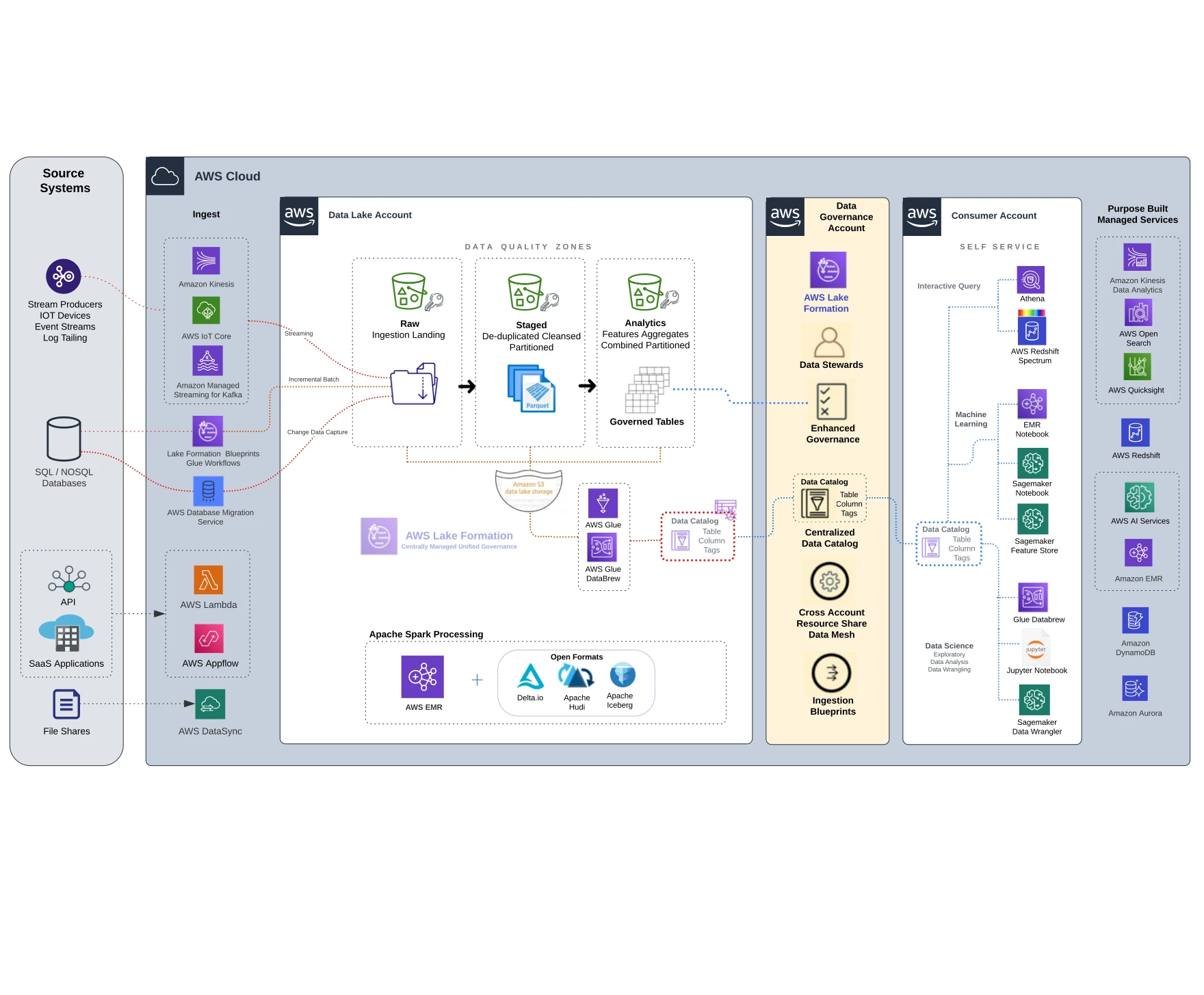
Accessible AWS Cloud Map Diagram
A key component of our data lake is how we set up the zones or buckets. The popular approach is to implement a multi-hop data architecture which allows us to deal with stages of data quality at each hop or zone.
One key difference exists when making the paradigm shift from traditional ETL to ELT. Traditional ETL bakes the transformation step into the middle of the extraction and loading process. This leads to ongoing maintenance costs and fragility since any changes require rewriting complex transformation logic code. ELT delays the transformation step until all data is loaded from the source system to the data lake destination. Benefits include: enabling continuous data loading, allowing as-needed application of transformations for analysis, eliminating break/fix maintenance, and facilitating the building of failure-proof data pipelines.
Landing
Sometimes, this additional landing pre-raw-zone is needed to work out extra complex ELT logic depending on the source system integration.
Raw
Land the data here; this is raw and volatile to failure. No modification is made to the data here and it can be reprocessed. If you consider brittle ETL processes, many data quality issues related to infrastructure, schema changes, breaking jobs, etc. are isolated to this zone and remediated here. It is highly desirable to stick to an ELT pattern in data pipelines.
Stage
The data are typically translated from the raw formats and extracted files to an optimized columnar format, like parquet. Typically, some light scrubbing and de-duplication are done at this stage. These data are in a data quality state of “usable” and ready for downstream consumption. These data provide a single version of the truth from which all downstream data wrangling flows. Automation of both data quality rules and privacy controls can be implemented in this zone. Examples include standardizing to common date formats and PII detection/remediation for compliance.
Analytics
The terminal data quality zone in the data lake is the analytics zone. Aggregated and curated datasets live here. This is an ideal location to save and share curated datasets. Data stewardship, managing folder locations, permissions, and sharing for datasets can be implemented in this zone.
The AWS Glue family of services includes tools to discover, integrate, prepare, clean, and transform data at any scale. ELT processing can be built with serverless glue data transformation activities as part of automated continuous data pipelines. Keeping our data moving and as fresh as possible through the quality zones in the data lake is critical. Additional operational features can be added such as feedback loops, SLA monitoring, and alerts on pipelines feeding the lake.
Additional activities for data quality handling in the lake can include:
Once ELT pipelines that continuously process data from raw to stage zones are in place, the next steps are governance, stewardship, metadata management, and enabling the self-service capability for data wrangling.
Using AWS Lake Formation, the data steward will set up the following:
Data stewards manage permissions and control metadata tagging and grouping of tags into categories, often referred to as taxonomies and ontologies in metadata management.
The key to enabling self-service is the existence of a centralized metadata catalog combined with a vital data governance stewardship function. With AWS Lake Formation, companies can set up centralized data governance on top of their data lakes. Self-service tools like Amazon Athena and AWS Glue DataBrew and Amazon SageMaker Data Wrangler are used to clean and prepare data sets for analytics and machine learning. These tools connect directly to AWS Lake Formation’s centralized data catalog for querying and analysis. Cleansed datasets are saved to the analytics zone; metadata is saved to the catalog.
The above approach connects knowledge workers to a continuous feed of trusted data. This means faster answers to business-critical questions. In gold mining, the more paydirt is moved through an efficient refining process, the more gold is recovered. Let us help you kick-start your “data refinery!”
Caylent’s data engineering experts will work with you to build a foundational data lake and enable your teams to use no-code solutions for wrangling and exploring your data. Our Serverless Data Lake Caylent Catalyst will shorten your time to market from months to weeks and set you up to grow your data lake easily by scaling ingest sources through low-code solutions.

Brian Brewer is a Principal Architect at Caylent, an industry product pioneer, data governance, and metadata expert. Brian has extensive experience innovating real-world products and solutions by solving challenging business problems. Brian earned multi-cloud certifications in Data Engineering, Big Data, and Data Science, and is an AWS Certified Data Analytics Professional.
View Brian's articlesCaylent Services
From implementing data lakes and migrating off commercial databases to optimizing data flows between systems, turn your data into insights with AWS cloud native data services.
Caylent Catalysts™
Rapidly implement a foundational low-code data lake with Caylent's data engineering experts who will also enable your teams for no-code exploratory data analysis.


Explore how Amazon ElastiCache for Valkey's new durability feature enables organizations to use it as a persistent data store for workloads such as AI agent memory, RAG knowledge bases, and real-time applications, while examining the tradeoffs.

Compare Amazon Kinesis Data Streams on-demand vs. provisioned pricing. See at what utilization levels provisioned mode saves money based on payload size and throughput.

Build a serverless data warehouse on AWS by streaming Amazon DynamoDB data to Amazon S3 with AWS Lambda. A cost-effective architecture for historical analytics and business reporting.