
Caylent Catalysts™
AWS Control Tower
Establish a Landing Zone tailored to your requirements through a series of interactive workshops and accelerators, creating a production-ready AWS foundation.
Learn how to implement disaster recovery capabilities for your Amazon Quantum Ledger Data Base to improve the availability of your applications across different regions or accounts
Disaster recovery is the process of maintaining or reestablishing vital infrastructure and systems following a natural or human-induced disaster. It involves policies, tools, and procedures to recover or continue operations of critical IT infrastructure, software, and systems. It is considered a subset of business continuity, explicitly focusing on ensuring that the IT systems that support critical business functions are operational as soon as possible after a disruptive event occurs. There are several approaches to it depending on the recovery time expected and the budget available. In this blog, we are going to focus on two main these:
Amazon Quantum Ledger Database (QLDB) is an AWS-managed ledger database that provides a complete and cryptographically verifiable history of all changes made to your application data.
Ledger databases are different from traditional databases in the way that the data is written in an append-only way, providing full data lineage. The data in these databases is immutable and verifiable. This can also be achieved in traditional databases, but it requires custom development.
QLDB is useful for those applications for which data integrity, completeness, and verifiability are critical. For example, for logistics applications that would need to store the movement between carriers and across borders, as well as in finance for tracking critical data, such as credit and debit transactions.
Although it is highly available across multiple AZs by its nature, it does not offer native support for snapshots of its data, nor cross-region replication or point-in-time recovery. It only gives the ability to export all queries executed between two dates to S3 in different formats, including ION and JSON.
The lack of native DR support is the main reason we decided to build a manual implementation of the strategies mentioned above for QLDB, which will be useful in case an application crucially needs to be highly available along different regions or accounts.
The following sections will describe the technique designed to provide disaster recovery capabilities over QLDB.
The solution we thought of to take regular backups is similar to the following:
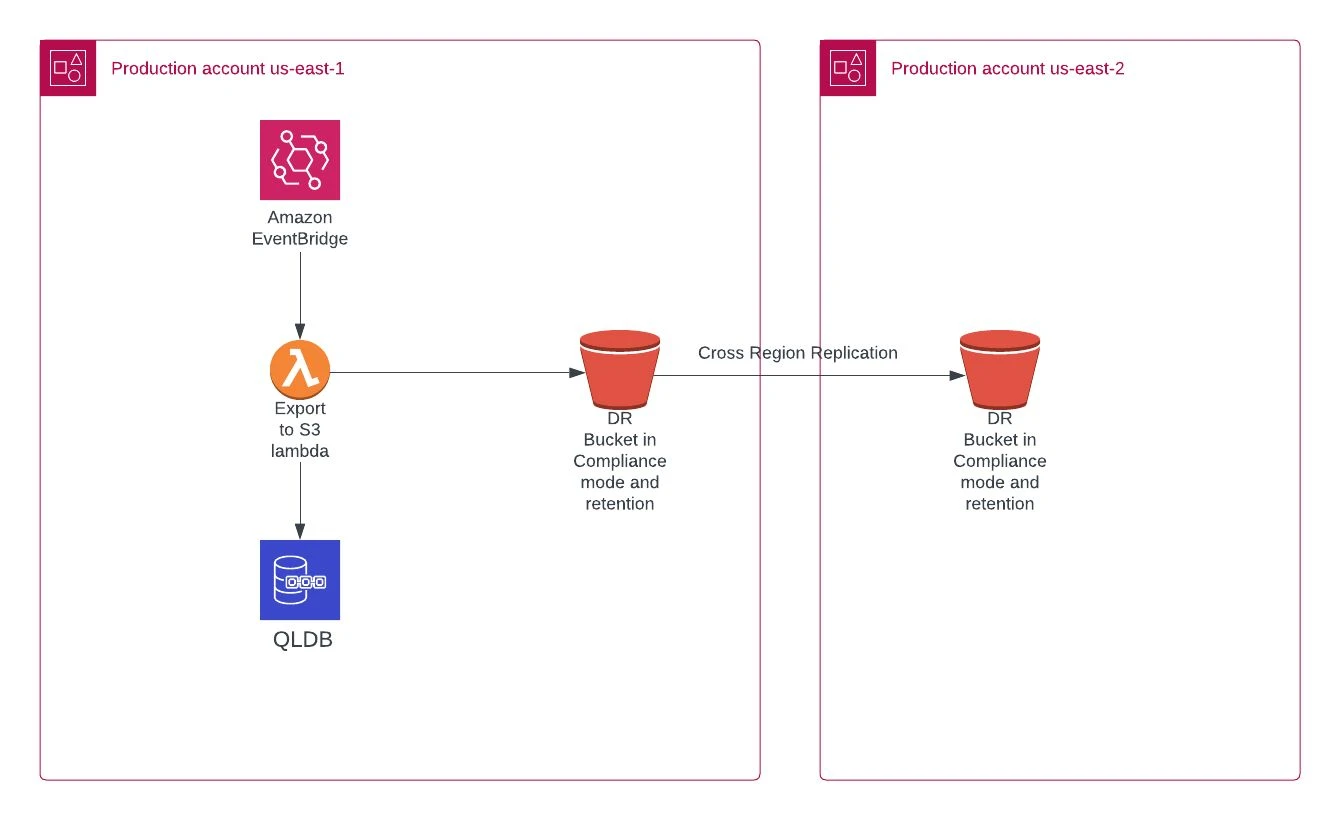
This architecture is composed of an EventBridge rule that will trigger a Lambda function each X amount of time. This X will depend on the RPO needed by the customer or application. In our case, it was triggered hourly.
The Lambda function is built in Python and will use boto3’s QLDB client to trigger the export to S3 given the start and end date and time (export_journal_to_s3 method):
"""
This Lambda is responsible for exporting the Ledger from the QLDB database to S3
"""
import os
from datetime import datetime, timedelta
import boto3
dr_bucket_name = os.getenv("DR_BUCKET_NAME")
ledger_name = os.getenv("LEDGER_NAME")
region = os.getenv("AWS_REGION")
role_arn = os.getenv("ROLE_ARN")
qldb_export_trigger_hour = os.getenv("QLDB_EXPORT_TRIGGER_HOUR")
# Configure the AWS SDK with your credentials and desired region
session = boto3.Session(region_name=region)
qldb_client = session.client("qldb")
def handler(event, context) -> tuple[int, dict]:
"""
Lambda entry point
event: object
Event passed when the lambda is triggered
context: object
Lambda Context
return: tuple[int, dict]
Success code and an empty object
"""
time_end = datetime.now().replace(minute=0, second=0, microsecond=0)
time_start = time_end - timedelta(hours=int(qldb_export_trigger_hour))
# Specify the QLDB ledger name and export configuration
export_config = {
"Bucket": dr_bucket_name,
"Prefix": "qldb-dr/",
"EncryptionConfiguration": {"ObjectEncryptionType": "SSE_S3"},
}
# Trigger the export by calling the ExportJournalToS3 API
response = qldb_client.export_journal_to_s3(
Name=ledger_name,
S3ExportConfiguration=export_config,
InclusiveStartTime=time_start,
ExclusiveEndTime=time_end,
RoleArn=role_arn,
OutputFormat="JSON",
)
# Print the export job ID
export_job_id = response["ExportId"]
print("Export Job ID: " + export_job_id)
return 200, {}
The destination S3 bucket, in this case, configured with compliance mode, will store the hourly backup files and will also have a cross-region replication configured to copy these files to another region. If, for any security or regulation reason, cross-account replication is also needed, this can be configured with no major issues.
An example of the content of these files is:
{
...
"transactionId":"A2mztA7Su6k5dRMQhOHN5C",
"transactionInfo":{
"statements":[
{
"statement":"SELECT * FROM information_schema.user_tables",
"startTime":"2023-05-24T17:00:33.988Z"
}
]
}
},
{
...
"transactionId":"A2mztA8BDHN5R62i10guzh",
"transactionInfo":{
"statements":[
{
"statement":"INSERT INTO test_account2 ?",
"startTime":"2023-05-24T17:11:17.098Z"
}
],
...
"revisions":[
{
"data":{
"uuid":"9eff5e3f-eb90-11ed-9a6e-0a3efd619f29",
"accountNo":268,
"accountName":"Miscellaneous Expenses."
},
...
}
Note that the export files contain ALL queries executed in the database, it can’t be configured to only export DDL/DML queries, so that is a point to have to take into account when restoring the data into the target database.
This backup workflow is independent of whether it is being used for the Backup & Restore or Warm Standby DR approaches. What can be modified depending on the chosen strategy is the interval between each QLDB export to S3.
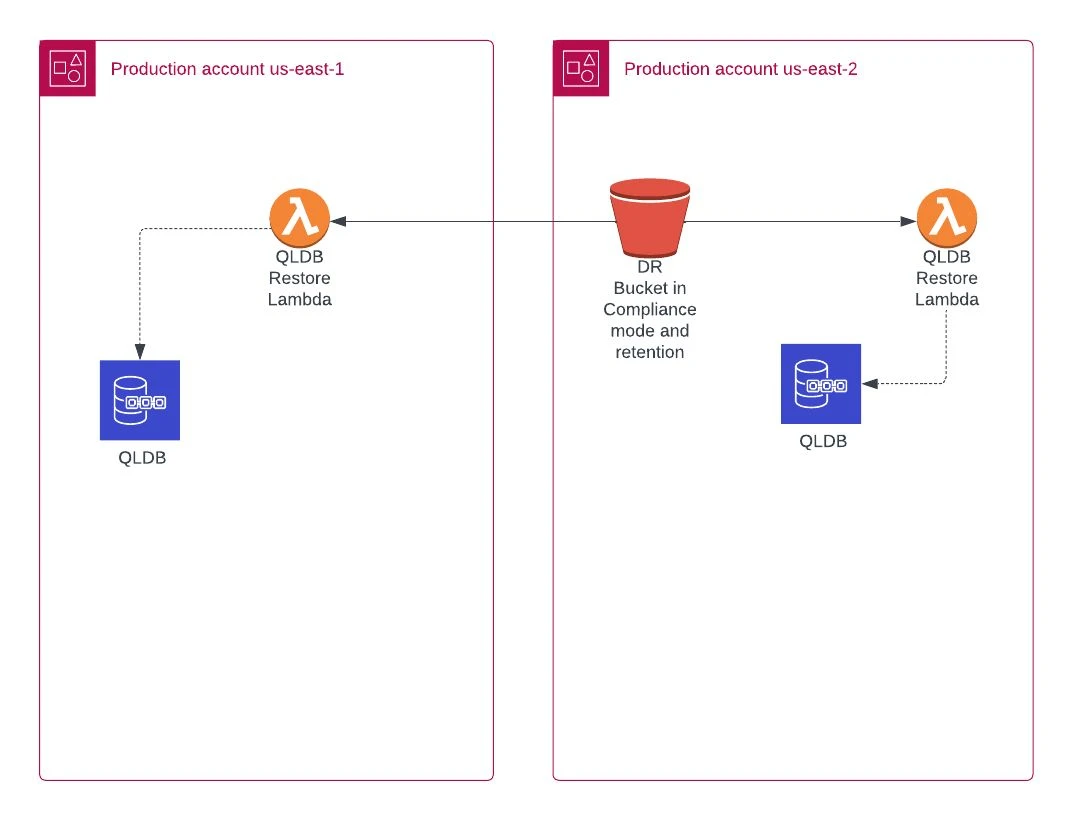
For this recovery approach, there are two lambdas responsible for restoring the data into the new QLDB database. In this example, we represent it in two regions to show that it is possible to restore it in the source/original region (in this case, on us-east-1) and so in the secondary region. Also, the bucket in the secondary region can be used to create a new QLDB in a different region than the principal or secondary.
The two-step lambda approach consists of:

"""
This Lambda is responsible for splitting up the load from
the QLDB exports distributes the load to be processed
by multiple Lambdas instances
"""
import os
import boto3
# Configure the S3 and SQS clients
s3_client = boto3.client("s3")
sqs_client = boto3.client("sqs")
# Retrieve the name of the source S3 bucket and target SQS queue from the event
source_bucket = os.getenv("DR_BUCKET_NAME")
target_queue_url = os.getenv("SQS_QUEUE_URL")
def handler(event, context) -> tuple[int, dict]:
"""
Lambda entry point
event: object
Event passed when the lambda is triggered
context: object
Lambda Context
return: tuple[int, dict]
Success code and an empty object
"""
# List all objects in the source bucket
try:
object_keys = []
paginator = s3_client.get_paginator("list_objects_v2")
pages = paginator.paginate(Bucket=source_bucket)
for page in pages:
for obj in page["Contents"]:
object_keys.append(obj["Key"])
except Exception as e:
print(f"DR Export Error when listing objects in bucket: {source_bucket}
{e}")
raise
# Push each object key to the SQS queue
for object_key in object_keys:
if object_key.endswith(".json"):
try:
sqs_client.send_message(
QueueUrl=target_queue_url,
MessageBody=f"s3://{source_bucket}/{object_key}",
)
except Exception as e:
print(f"DR Export Error when publishing message to SQS queue {e}")
raise
return 200, {}
"""
This Lambda is responsible for restoring the Ledger from the S3 backup bucket to QLDB database
"""
import os
import json
import awswrangler as wr
import botocore
from pyqldb.config.retry_config import RetryConfig
from pyqldb.driver.qldb_driver import QldbDriver
region = os.getenv("AWS_REGION")
ledger_name = os.getenv("LEDGER_NAME")
def handler(event, context) -> tuple[int, dict]:
"""
Lambda entry point
event: object
Event passed when the lambda is triggered
context: object
Lambda Context
return: tuple[int, dict]
Success code and an empty object
"""
# Reading from SQS queue
for record in event["Records"]:
s3_path = record["body"]
file_dataframe = wr.s3.read_json(path=s3_path, lines=True)
df_to_json_array = json.loads(file_dataframe.to_json(orient="records"))
docs_to_insert = []
for item in df_to_json_array:
for statement in item["transactionInfo"]["statements"]:
if (
statement["statement"]
.upper()
.startswith(("INSERT INTO", "UPDATE", "DELETE"))
):
docs_to_insert.append(
{
"statement": statement["statement"],
"data": item["revisions"][0]["data"],
}
)
driver = QldbDriver(
ledger_name=ledger_name,
retry_config=RetryConfig(retry_limit=0),
config=botocore.config.Config(
retries={"max_attempts": 0},
read_timeout=10,
connect_timeout=10,
),
region_name=region,
)
try:
for doc in docs_to_insert:
driver.execute_lambda(
lambda x: x.execute_statement(doc["statement"], doc["data"])
)
except Exception as e:
print("DR Restore Error in file:" + s3_path + str(e))
raise
print("Restored file:" + s3_path)
return 200, {}
In this approach, the RTO tends to be higher, or depends linearly on the amount of queries to re-run. On the other hand, the cost will be significantly reduced as we are going to pay only for the backup’s storage and one QLDB storage and reads/writes.
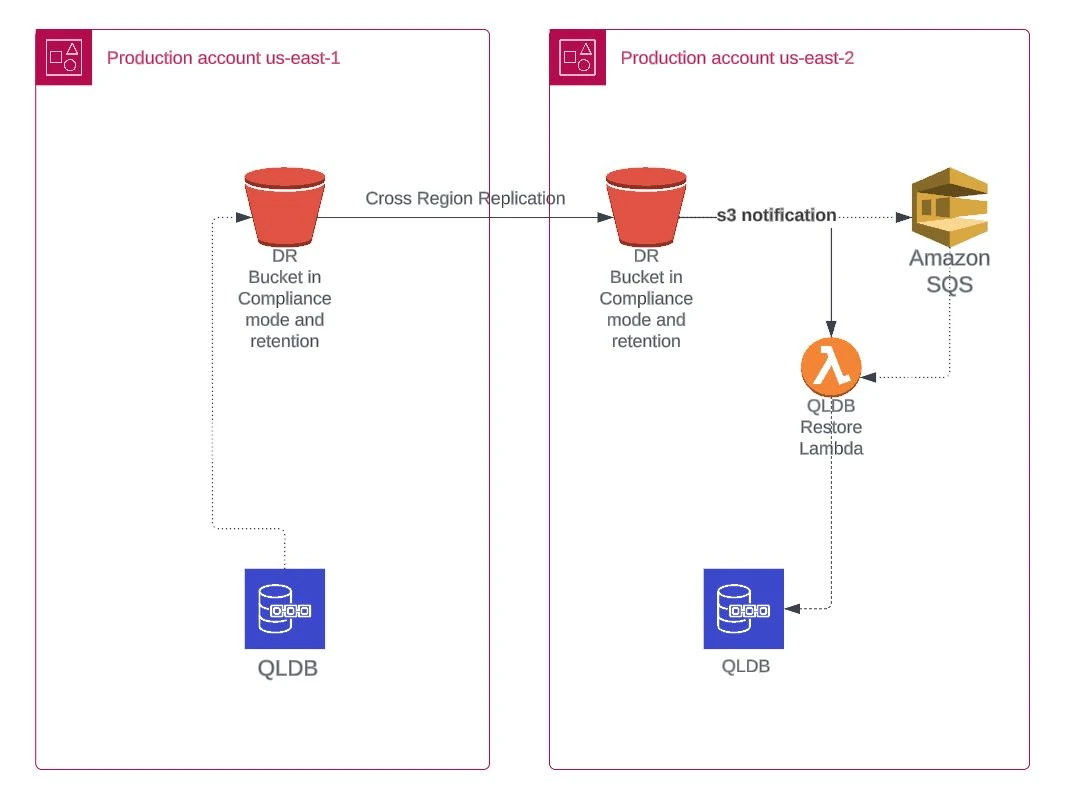
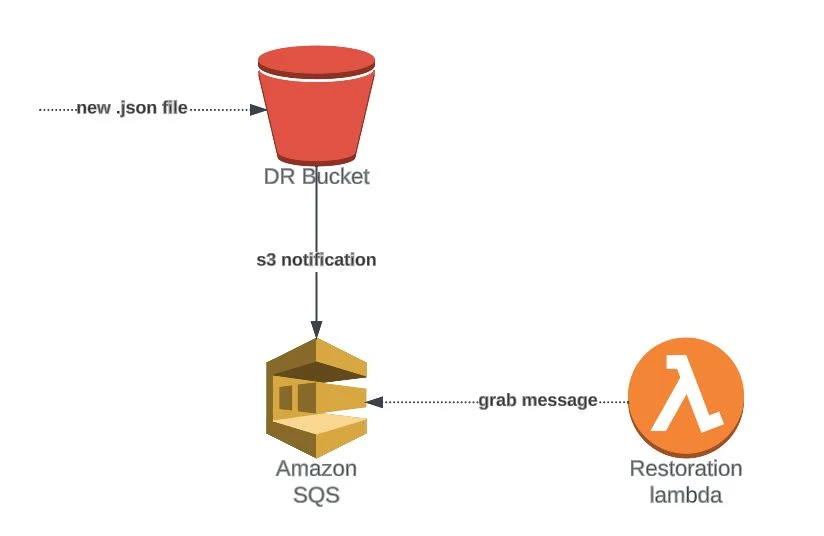
In this case, the workflow is similar to the previous one. The only difference is that the first lambda, the SQS-distribution, will not be necessary because we are going to configure the DR bucket to publish the message in the queue using S3 notifications.
After that step, the Restoration Lambda will work exactly the same as in the Backup & Restore strategy.
This solution has some pros and cons compared to the previous one. As a pro, this approach would have a very fast RTO as the database is already loaded and running. As a con, the cost of the solution will be higher: we will have to pay double for the QLDB storage costs and the writes to the DB, because we will have two copies of the data (or more, depending on the number of backup regions that we configure); on the other hand, we will pay once for reads as these only go to the active database.
To take advantage of some of the pros and get rid of some cons of both previous solutions, we can build an intermediate where we try to keep the backup DB “mostly” up to date.
This approach is useful when we have a lot of historical data to reprocess. We would have to skip the most recent backups and only process the older ones. This way, we will pay less than double the storage and writes (the backup DB will have less data), and the RTO will be significantly reduced because the database will be nearly up to date.
This solution can be achieved by executing an initial load of the older backups just by adopting the Backup & Restore option and filtering which files to send to the second region. Once the backup database is loaded with the older data, the solution to adopt will be similar to the original, with all the involved services (QLDB, S3) waiting for the disaster to happen to start the load of the newer backup files.
This proposed architecture is only a possible solution to the lack of DR support in QLDB.
Even though QLDB is a new service, we consider that it fits all the business requirements which it was created for. It is managed by AWS, so you don’t have to worry about handling infrastructure configurations, and it’s highly available.
The only element against it is that we can find it does not have a native DR strategy or native backups support. We believe that AWS will eventually develop something related to that in the future, but as for now, this is the suggestion for solving this limitation.
The main purpose of this blog was to give a brief idea of what available functionalities we can use to build a homemade strategy in case a disaster happens in our production environment. We know that it can be improved or adjusted depending on the use case or on the database load or size, and we recommend so in case these solutions are not feasible in your environment.
A recommendation that we can give is to try to build a process, maybe in a nightly job, to try to clean and merge the content of the files, for example, deleting all the transactions that we don’t want, like the SELECTs. This way, we will have fewer and smaller backup files to load, which will reduce storage and processing costs.
Caylent can help set you up for innovation and success on the AWS Cloud. Get in touch with our team to discuss how we can help you achieve your goals.

Franco Balduzzi is a Sr Data Engineer with 6 years of experience developing data solutions for different industries, including medical, consulting, and finance/banking. He graduated in Systems Engineering in 2019, and his strongest skills are data-related AWS and GCP cloud computing technologies. He likes to build highly-available and performant end-to-end solutions. Being a proactive person, he is always open to help and contribute with his partners, because he maintains that “you like to be helped when you are in a rush”.
View Franco's articles
Jorge Goldman is an Engineering Manager with over 12 years of experience in diverse areas from SRE to Data Science. Jorge is passionate about Big Data problems in the real world. He graduated with a Bachelors degree in Software Engineering and a Masters degree in Petroleum Engineering and Data Science. He is always looking for opportunities to improve existing architectures with new technologies. His mission is to deliver sophisticated technical solutions without compromising quality nor security. He enjoys contributing to the community through open-source projects, articles, and lectures, and loves to guide Caylent's customers through challenging problems.
View Jorge's articles

Explore how ACGR in CxPortal extends Amazon Connect Global Resiliency by giving contact center operations teams a centralized, playbook-driven way to execute, manage, and monitor regional failover and recovery, reducing downtime and accelerating response during service disruptions.

Discover how Amazon Q Developer is redefining developer productivity - featuring a real-world migration of a .NET Framework application to .NET 8 that transforms weeks of manual effort into just hours with AI-powered automation.

Learn best practices for building resilient IT systems on AWS to ensure reliability, security, and high availability in the face of failures and disruptions.