All the needed infrastructure will be provisioned using AWS CloudFormation as the Infrastructure as Code (IaC) tool. To implement the above diagram, we’ll follow these steps:
- Create the data stream where the producer (instance) will publish the data (application logs).
- Create and configure OpenSearch where all the logs will be stored and also visualized using Kibana.
- Create the delivery stream that will be the bridge between the data source and target.
Creating a Kinesis Data Stream
Let’s start with the first step: data stream creation. Below is an example showing how to create a Kinesis Data Stream using IaC with CloudFormation. There are two ways of provisioning a Kinesis Data Stream: ON_DEMAND and PROVISIONED. For small and medium applications we should leverage the ON_DEMAND stream mode, which avoids the complexity of calculating capacity (Kinesis Shards).
“A shard is a uniquely identified sequence of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity. Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys).” - Kinesis Components Documentation.
KinesisDataStream:
Type: AWS::Kinesis::Stream
Properties:
Name: !Sub ${kinesisDataStreamName}
StreamModeDetails:
StreamMode: ON_DEMAND
Provisioning and Configuring OpenSearch
Going to the next step, we need to provision and configure OpenSearch. Since we’re using OpenSearch Serverless, we don’t need to provision a cluster and it will only be necessary to create an OpenSearch collection. A collection is a logical grouping of one or more indexes where the application logs will be aggregated. Once the collection is created an endpoint will be available to access and manage the streamed data through a UI (with Kibana).
ApplicationLogsCollection:
Type: 'AWS::OpenSearchServerless::Collection'
DependsOn:
- OpenSearchEncryptionPolicy
- OpenSearchNetworkPolicy
- OpenSearchAccessPolicy
Properties:
Name: !Sub ${openSearchCollectionName}
Type: SEARCH
After creating the OpenSearch collection we need to create three required policies: Data Access, Network, and Encryption Policies.
Data Access Policy: This policy specifies the resources (users and roles) that can have access to the OpenSearch collection, indexes and dashboard.
OpenSearchAccessPolicy:
Type: 'AWS::OpenSearchServerless::AccessPolicy'
Properties:
Name: collection-access-policy
Type: data
Policy: !Sub >-
[{
"Description":"Access for test-user",
"Rules":[{
"ResourceType":"index",
"Resource":["index/*/*"],
"Permission":["aoss:*"]
},{
"ResourceType":"collection",
"Resource":["collection/${openSearchCollectionName}"],
"Permission":["aoss:*"]
}],
"Principal":[
"arn:aws:iam::${AWS::AccountId}:user/${openSearchUser}",
"${DeliveryRole.Arn}"
]
}]
Looking at the Principal block in the above CloudFormation a bit closer, we’re specifying the user, ${openSearchUser}, can have access to the dashboard, to all indexes, and to the OpenSearch collection we’re creating, ${openSearchCollectionName}. Adding the role, ${DeliveryRole.Arn}, as a Principal means that we’re allowing that DeliveryRole role, which is assumed by the Kinesis Firehose service to publish data to the OpenSearch collection.
Network Policy: This policy specifies whether OpenSearch resources, the collection, and dashboard are accessible from the public internet or only from the internal AWS network via Amazon VPC endpoints. We’re explicitly allowing public access with the AllowFromPublic flag set to true.
OpenSearchNetworkPolicy:
Type: 'AWS::OpenSearchServerless::SecurityPolicy'
Properties:
Name: collection-network-policy
Type: network
Policy: !Sub >-
[
{
"Rules":[{
"ResourceType":"collection",
"Resource":["collection/${openSearchCollectionName}"]
}, {
"ResourceType":"dashboard",
"Resource":["collection/${openSearchCollectionName}"]
}],
"AllowFromPublic":true
}
]
Encryption Policy: Encryption at rest is required for serverless collections, and you have two options. The first option is to specify an encryption key from AWS Key Management Service (KMS) or if you don’t want to create or use a specific encryption key, you can just set the AWSOwnedKey to true and AWS will manage the encryption key for you.
OpenSearchEncryptionPolicy:
Type: 'AWS::OpenSearchServerless::SecurityPolicy'
Properties:
Name: collection-encryption-policy
Type: encryption
Policy: !Sub >-
{
"Rules":[{
"ResourceType":"collection",
"Resource":["collection/${openSearchCollectionName}"]
}],
"AWSOwnedKey":true
}
Having the OpenSearch collection and its required policies set, the next step is to configure the Kinesis Delivery Stream (Firehose). In the CloudFormation script below, we’re specifying a Kinesis Data Stream as the source for our data under KinesisStreamSourceConfiguration, and the OpenSearch collection as the destination using CollectionEndpoint.
When configuring the Kinesis Delivery Stream, it’s important to enable Amazon CloudWatch logs for the data ingestion on the OpenSearch collection and also for the Amazon S3 backup errors, otherwise we won’t be able to debug the stream pipeline.
Since we’re configuring an OpenSearch collection as the destination for the delivery stream, it’s necessary to specify an index where all the streamed data will be aggregated; that’s the IndexName field below. The specified index will be created automatically so it isn't necessary to create it using the UI.
As specified on the diagram, the Firehose service will be polling data from the data stream and pushing it to the OpenSearch collection. We need to configure the periodicity for the data polling interval, which is in the BufferingHints configuration below. It’s defined in seconds and there is a tradeoff: using a lower number for your polling interval can decrease latency and improve real-time processing, but it is also more expensive so be sure to find the right balance for your needs.
KinesisDeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
DependsOn:
- KinesisDataStream
- ApplicationLogsBucket
- ApplicationLogsCollection
Properties:
DeliveryStreamName: !Sub ${kinesisDeliveryStreamName}
DeliveryStreamType: KinesisStreamAsSource
AmazonOpenSearchServerlessDestinationConfiguration:
IndexName: application-logs-index
CollectionEndpoint: !GetAtt ApplicationLogsCollection.CollectionEndpoint
RoleARN: !GetAtt DeliveryRole.Arn
BufferingHints:
IntervalInSeconds: 60
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: !Sub '/aws/kinesisfirehose/${kinesisDeliveryStreamName}'
LogStreamName: "destination-logs"
S3Configuration:
BucketARN: !GetAtt ApplicationLogsBucket.Arn
RoleARN: !GetAtt DeliveryRole.Arn
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: !Sub '/aws/kinesisfirehose/${kinesisDeliveryStreamName}-backup'
LogStreamName: "backup-logs"
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt KinesisDataStream.Arn
RoleARN: !GetAtt DeliveryRole.Arn
The last step is to handle service permissions using roles, policies and permissions. Since Kinesis Delivery Stream (Firehose) is polling data from Kinesis Data Stream, populating an OpenSearch collection, publishing logs on CloudWatch, and saving backup logs on S3, all of the required permissions need to be explicitly declared. My advice is don’t worry about memorizing any permissions names or settings as all of them are well described in the AWS documentation. As a trick to help you assign the correct permissions to your policy, you can create the resource manually using the console and copy the automatically generated permissions to your CloudFormation script.
DeliveryRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Sid: ''
Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: 'sts:AssumeRole'
DeliveryStreamPolicy:
Type: AWS::IAM::Policy
Properties:
Roles:
- !Ref DeliveryRole
PolicyName: firehose_delivery_policy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:AbortMultipartUpload
- s3:GetBucketLocation
- s3:GetObject
- s3:ListBucket
- s3:ListBucketMultipartUploads
- s3:PutObject
Resource:
- !GetAtt ApplicationLogsBucket.Arn
- !Join
- ''
- - !GetAtt ApplicationLogsBucket.Arn
- '/*'
- Effect: Allow
Action:
- kinesis:DescribeStream
- kinesis:GetShardIterator
- kinesis:GetRecords
- kinesis:ListShards
Resource:
- !Sub 'arn:aws:kinesis:${AWS::Region}:${AWS::AccountId}:stream/${kinesisDataStreamName}'
- Effect: Allow
Action:
- es:DescribeElasticsearchDomain
- es:DescribeElasticsearchDomains
- es:DescribeElasticsearchDomainConfig
- es:ESHttpPost
- es:ESHttpPut
Resource:
- !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%'
- !Sub 'arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%/*'
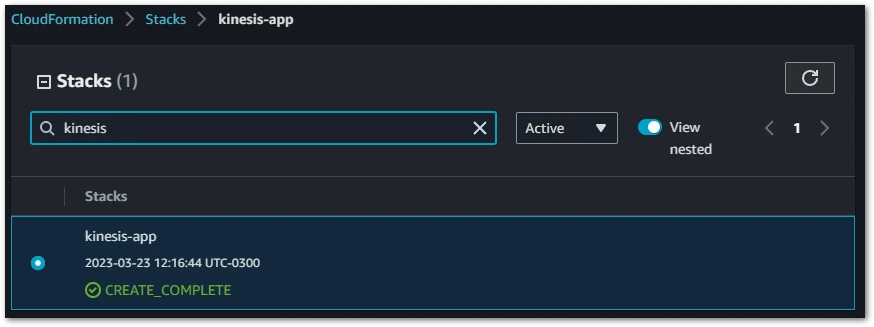
Once you have the CloudFormation script ready for deployment, you can run it like this from the command line:
$ aws cloudformation deploy --template-file .\template.yml --stack-name kinesis-app --capabilities CAPABILITY_IAM
NOTE: When you are managing AWS IAM resources through CloudFormation remember that it's necessary to specify the capability value using CAPABILITY_IAM - just like Linux capabilities.
After running the above command, all your resources should be created and you’ll have something like this:
Created Resources:
- Kinesis Data Stream
- Kinesis Delivery Stream
- OpenSearch Collection
- OpenSearch Data Access, Network, and Encryption Policies
- S3 bucket for backup logs errors
- Kinesis Delivery Stream Role and Policy
You can find the complete CloudFormation script here.
Publishing data from Kinesis
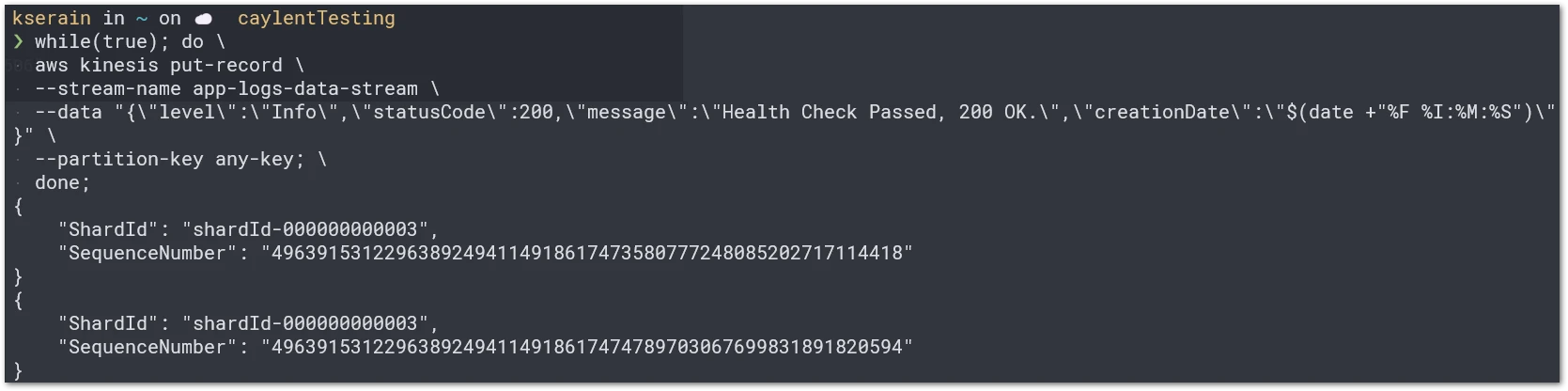
Now that the streaming infrastructure is ready, we have what we need to start publishing data on the Kinesis Data Streams. There are many ways to publish our application logs on the Kinesis Data Streams. We could write an application or an AWS Lambda function to do it using the Kinesis Software Development Kit (SDK), or we could create a producer using the Amazon Kinesis Producer Library (KPL), but for demonstration purposes we’re going to use the good ol’ AWS Command Line Interface (CLI). This is the command structure:
$ aws kinesis put-record --stream-name <STREAM_NAME> --data <STRING> --partition-key <PARTITION_KEY>;
Below, is the command with all of the parameters set, and by putting it inside a do-while loop we will simulate data being streamed continuously:
$ while(true); do \
aws kinesis put-record \
--stream-name app-logs-data-stream \
--data "{\"level\":\"Info\",\"statusCode\":200,\"message\":\"Health Check Passed, 200 OK.\",\"creationDate\":\"$(date +"%F %I:%M:%S")\"}" \
--partition-key any-key; \
done;
Running the above command should generate something like this:
Note: Once you run the above command, use CTRL + C, for breaking the loop and releasing the terminal.
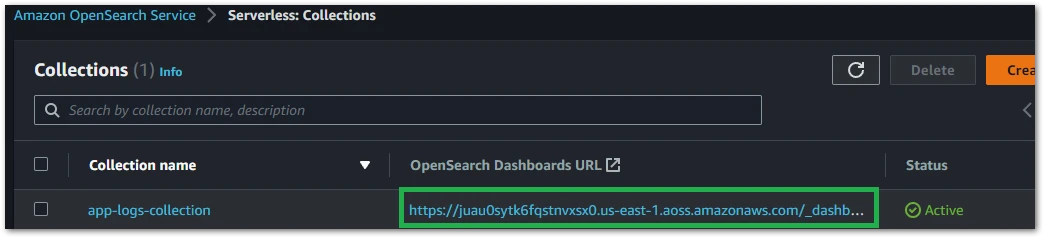
With that being done, the Kinesis Delivery Stream (Firehose) is now receiving data from the Kinesis Data Stream every 60 seconds (BufferingHints) and sending it to the OpenSearch collection. Next, to see the data on the UI, we can grab the Kibana URL from the collection resource.
To sign-in, you need to use the access key and secret key from the specified user on the OpenSearch Data Access Policy.
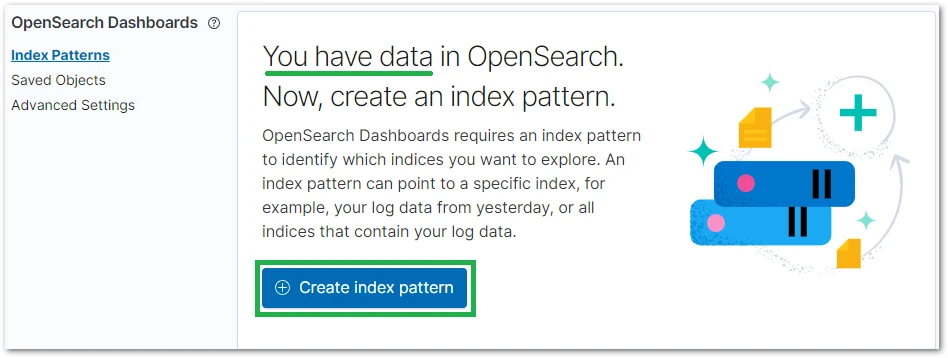
Before having access to the streamed data, you’ll see that Kibana suggests creating an index-pattern. An index-pattern is a regex (regular expression) to aggregate data from multiple indexes. As we have only one, we can put the index name previously specified on the CloudFormation - application-logs-index.
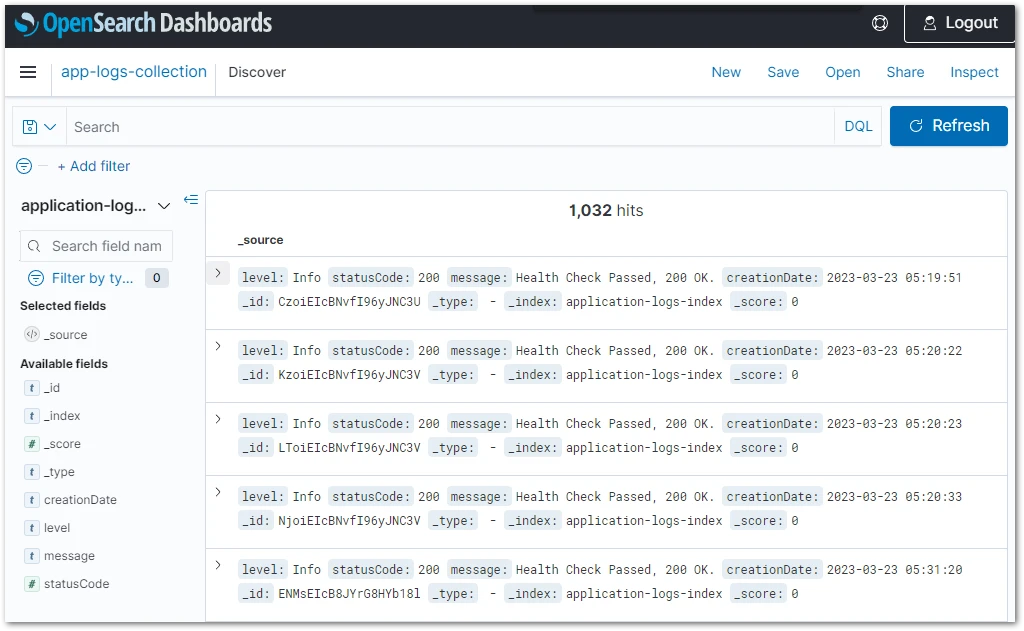
Because we created the index pattern under the Discover menu, we are already able to see the application logs that we streamed from bash. As you can see below, there are more than one thousand log entries.
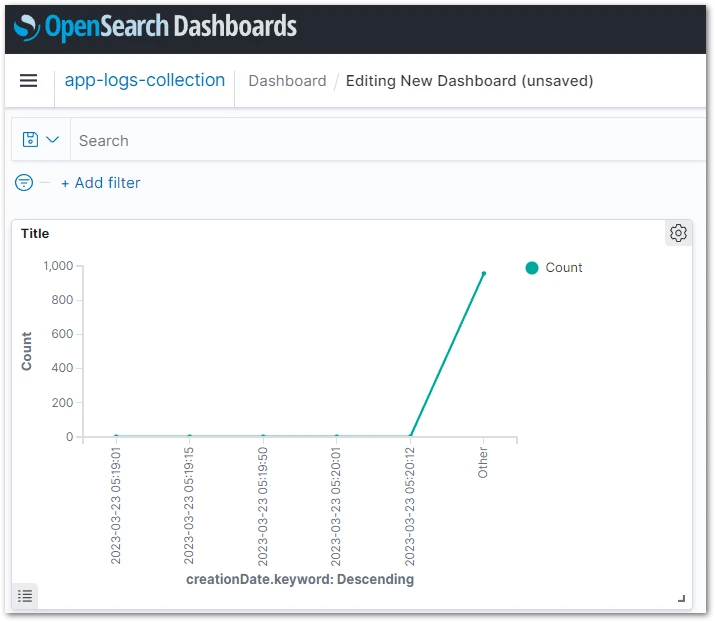
Now, you are only limited by your imagination! For example, an Observability Engineer could extract many metrics from a data warehouse like that. For demonstration purposes, let’s plot that data on a line graph.
Yes, the magic is happening! We are receiving streamed data and creating visualizations using OpenSearch. The next steps are up to you!
Once you are done, and to avoid any billing surprises, be sure to delete the entire stack by running:
$ aws cloudformation delete-stack --stack-name kinesis-app
Conclusion
We could have used Kinesis for streaming to different targets as approached here, but OpenSearch it’s a powerful tool that deserves highlight since it can be used for more than just application logs; You can also leverage OpenSearch for your SIEM (Security Information and Event Management) stack - For gathering security insights and metrics from your application on AWS. We hope to share more OpenSearch use cases in the future.
Understanding how to set up and implement data streaming can open up many new ideas and opportunities. What you learned here about streaming application logs to OpenSearch Serverless is just one example on how to create near real-time integrations without writing a line of code. Data Streaming implementations, gives you the chance to add value to the business faster, since you don’t need to unnecessarily spend time on building custom technical processes and reinventing the wheel.
Next Steps
If you’re ready to simplify how you ingest, search, visualize, and analyze your data, Caylent's experts can help you leverage Amazon OpenSearch. Get in touch with our team to discuss how we can help you achieve your goals.