
Caylent Services
Cloud Native App Dev
Deliver high-quality, scalable, cloud native, and user-friendly applications that allow you to focus on your business needs and deliver value to your end users faster.
Learn how some of the newest services released from AWS re:Invent 2022 can help cloud native application developers save time, reduce complexity and improve the resiliency of deployments.
For years, re:Invent has continued to grow in popularity. It’s a fantastic experience complete with exciting venues, fun events, the best of social networking, and yet still, the service and feature announcements always stand out as the biggest take-away. Well, that and the swag. As the portfolio of AWS (and Amazon) Services grows, launch announcements become more and more difficult to process. What might excite me about developer experience may not be as resounding to someone with a career focus on virtual networking. Conversely, many of the announcements flow in one ear and out the other when it comes to use cloud-native developers. This year, however, has been an absolute playground of new application development features and patterns. If you develop applications atop AWS services, especially those using serverless patterns, here are three announcements that will save you time, reduce complexity, and improve resiliency, that you simply cannot miss.
For years, Amazon Elastic Container Service (ECS) has been a staple orchestrator for container-based workloads at AWS. Its reliability and relatively low learning curve have led to broad adoption. Many customers, myself included, have found that scaling large architectures on Amazon ECS often requires dawning the administrative overalls and farming a herd of load balancers to manage service-to-service communication. You may have yourself built something resembling this:
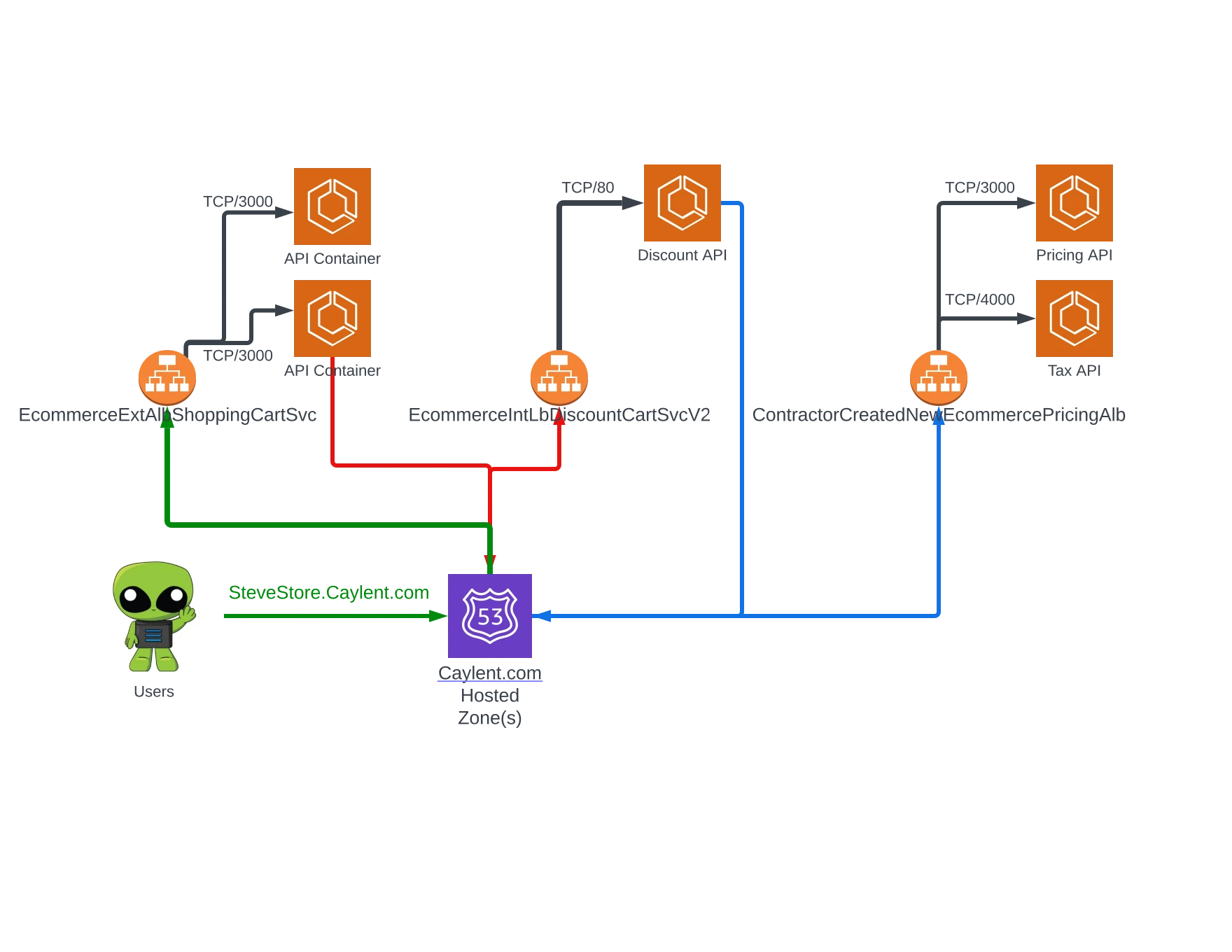
It works, sure, but the added costs of load-balancers, combined with the additional resources requiring review during diagnostics, left even the die-hard Amazon ECS fans wanting something more manageable. If you have ever made a typo in a mid-tier load-balancer health-check, you know that specific variety of goose-bumps this can instill. Service Discovery, AWS Cloud Map, and similar solutions go a long way towards reducing the number of load-balancing resources required, but they, too, come with additional learning curves, implementation demands, and so on. The introduction of Service Connect drastically lowers the entry barrier into AWS Cloud Map.
Service Connect is an Amazon ECS-native interface to AWS Cloud Map, allowing Amazon ECS services to define meaningful logical names with which they can communicate. Services can act as Clients, Servers, or both in the model, and the necessary configuration to resolve the logical names of each service is provided by Amazon ECS at runtime. Speaking of names, there are many to choose from…
Perhaps the only confusing implementation detail of Service Connect is that you can configure Discovery Names, Client Aliases, and Port Names for the resolution of a specific endpoint within a service, and there is a light hierarchy in how these values get rolled up into an AWS Cloud Map namespace. You can read a detailed description within the Amazon ECS Develop Guide, but they essentially work like this:
Each endpoint is an exposition of a port hosted within your Amazon ECS service, which is provided a port name. Atop these named ports, you may define a Client Alias that represents the service within AWS Cloud Map (that then points back to the named port). An optional Discovery Name can be layered atop the Client Alias, but if none is provided, the Client Alias is used for this value also.
…No one ever accused AWS of being good at naming things, but in this case, we can take some advantage through variety. The useful thing about having the additional Discovery Name layer, is that you can define a technically meaningful DNS name strategy while presenting friendly names to service consumers. Afterall, “database” has a much more meaningful connotation than “ecs-new-docker-postgresql-alpine.interal”. For a more practical demonstration, take a look at how we can compress our prior example, leveraging Service Connect to reduce the complexity and make the entire architecture easier to reason about:
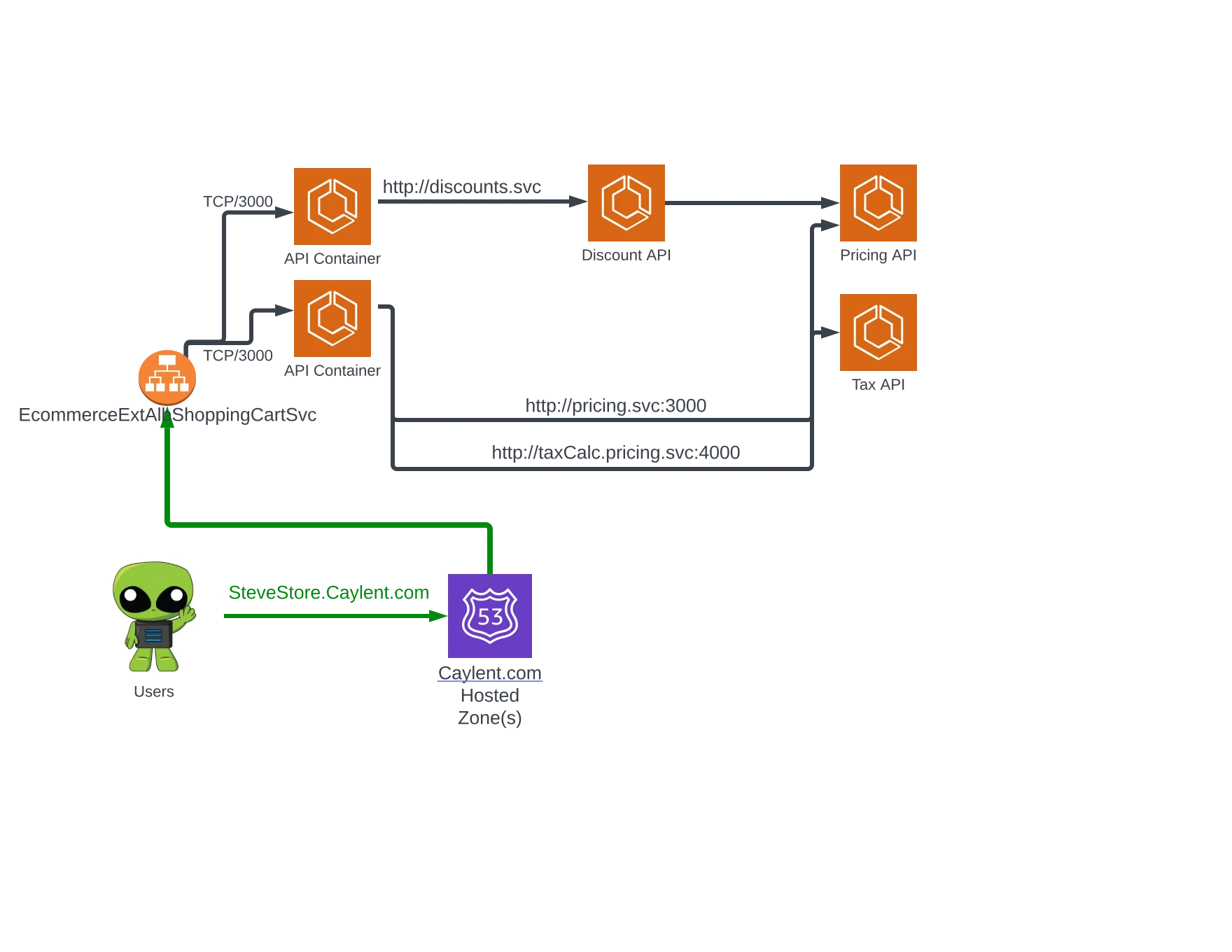
Service Connect provides an exciting opportunity to take advantage of a service-mesh like approach to logical addressing in Amazon ECS. Before you get started with this new feature, there are a couple of caveats to consider. To handle the routing of requests in this new model, Service Connect injects a container into each Amazon ECS task, much like the sidecar architecture patterns used with Envoy and similar mesh solutions. This sidecar consumes Amazon ECS compute resources and may require some reconfiguration of existing task definitions to ensure desired performance. The addition of this injected container also means that previously existing tasks cannot participate in Amazon ECS Service Connect, those tasks must be administratively upgraded to support the feature, which involves some reconfiguration and a restart of those tasks.
Though the sidecar pattern might give some administrators heartburn to start (given it somewhat magically appears), the ability to reduce dependency on load balancers for routing and the clarity added through friendly service names, brings a lot of value into the Amazon ECS ecosystem without relying on complex third-party mesh systems. It will be exciting to see how this feature continues to grow and what it may one day allow us to further simplify in our Amazon ECS-based applications.
Anyone who has had to sell AWS Lambda as a compute model, be it to customers or internal stakeholders, has eventually heard the same question:
“How do I know if my AWS Lambda functions are vulnerable, dangerous, etc. etc. ”
It is a valid question. After all, as consumers of the AWS Lambda service, we are handing over a piece of code and asking for it to run at potentially massive scales. For many customers, AWS Lambda adoption represents their first venture into serverless and microservice development, which in itself can create anxiety. If that code can conceivably contain vulnerabilities, the management of related risks, and the anxiety of planning mitigation strategy, too can scale in tandem.
As AWS Lambda has matured and its use has become more commonplace, it has been a reasonably addressable question. The industry has stepped up and offered many third-party solutions to statically analyze AWS Lambda function code during the development process. Solutions even exist to run underneath AWS Lambda functions at runtime using layers to ensure that policies like egress filtering are honored. Like any non-native solution, these answers to the question have involved additional processes, more complexity in pipelines, diagnostic burden (in the case of layers), and additional vendor management activities. This year, Amazon Inspector gives us something a little closer to home.
Amazon Inspector, the cloud-native security and scanning service used across AWS, now supports vulnerability scanning for AWS Lambda functions. Once activated, this new Inspector feature can scan all the lambda functions in an AWS organization. Customers can exclude accounts and individual functions from scanning as desired for more granular control of findings. When a vulnerability is found, Amazon Inspector creates and distributes findings to AWS Security Hub and Amazon Event Bridge so that existing policies and procedures can be adapted to include responses to AWS Lambda-specific vulnerabilities.
Inspector initially scans functions when they are deployed or updated, but also reactively scans when a new CVE is added to Amazon’s database. Existing functions will also be discovered periodically (which AWS indicates may take up to an hour). The continued scanning of functions throughout their lifecycle, and as a response to new CVEs, provides confidence to developers and business stakeholders that regular auditing of their code is performed; All without the need for added complexity or reliance on a third-party vendor.
Just as AWS Lambda has eased the adoption of cloud-based computing, their interface with Amazon Inspector is easing the adoption of security best practices. It’s an exciting first step toward a risk-management-influenced approach to cloud-native application development.
SnapStart is a feature years in the making, and it solves a very complex problem, cold starts. For the uninitiated, a cold start refers to the amount of time it takes for an AWS Lambda function, or more specifically, the execution environment upon which it runs, to respond to its first request. Cold starts occur whenever an execution environment supporting a AWS Lambda function must be “warmed up” or otherwise made ready to accept an invocation. This happens when a function is first deployed, after being re-awakened from a period of no requests (commonly referred to as falling asleep), or during scaling events. Each execution environment can handle a finite number of simultaneous invocations, so functions experiencing spikes in demand may scale drastically and introduce several cold starts when additional execution environments must be warmed up to support the load.
Imagine, if you will, serving a dining room filled with thousands of hungry people, but you only had ten microwaves with which to prepare food. Periodically you would be able to serve bursts of requests, but then you would have to reload the microwaves before more food was ready. Wouldn’t it be better to have some pre-warmed food ready to go?

Be it a microwave meal or the foundation of your critical customer-facing API, The penalty of a cold start is always time. For those user-facing activities, it’s a price developers don’t want to pay when it slows the user experience. Being one of the heavier platforms, Java developers have often suffered this penalty most.
Java functions in AWS Lambda have historically endured higher cold start penalties than those built on lighter runtimes like JavaScript and Python. Aside from the JVM itself, java functions also tend to include complex collections of libraries to work with frameworks like Spring Boot, requiring several seconds to warm up. This means that APIs and other services using such functions for computing could take a long time to respond, and that response time could fluctuate wildly at scale. This year, the AWS Lambda team took a huge first step toward solving the problem, and no, it’s not a bigger microwave (though we at Caylent would love to hear what name they would give to ‘microwave as a service’).
The introduction of AWS Lambda SnapStart greatly reduces cold starts for Java functions. SnapStart leverages the Snapshotting features of the Firecracker virtual machine allowing the AWS Lambda Service to pre-warm copies of the Java internals when a function is created and then reuse them when new execution environments are needed. This allows Java functions to start and scale at a fraction (their own blog quotes a reduction from 6000ms to 200ms) of the time.
Implementation of SnapStart is easy. Developers simply enable the feature on the function using whatever deployment mechanism they have, and support for Infrastructure as Code tooling is quickly being updated across the industry. There are a few caveats to consider, though, before diving in.
Today SnapStart is only available for Java and only for those functions using Correto Java 11. Additionally, as SnapStart is snapshotting the Init portion of the AWS Lambda function lifecycle, any use of long-lived connections and ephemeral data may require special handling. For most of us, that means moving some things back into the function handlers and checking the state of any temporary directories. In our opinion, restarting the database connection could be a small price to pay for the cold start savings, but your mileage may vary.
Tackling cold starts is an amazing thing to see come out of the AWS Lambda team and demonstrates their dedication to providing computing capabilities for even the most time-sensitive workloads. According to AWS, we can look forward to the addition of more runtimes to SnapShot and some great industry examples of its use in the future.
Enjoying our re:Invent 2022 content? Read through our recaps of the keynotes and major announcements, on our blog. If you’d like to leverage our AWS expertise for projects ranging from cloud migrations & modernizations to data analytics, AI & Machine Learning, get in touch with our team!



Explore all of the launches and capabilities announced at the 2026 AWS Summit in New York City, including Amazon Bedrock Managed Knowledge Base, AgentCore harness, AWS Context, and AWS Continuum.

Explore how Amazon ElastiCache for Valkey's new durability feature enables organizations to use it as a persistent data store for workloads such as AI agent memory, RAG knowledge bases, and real-time applications, while examining the tradeoffs.

If you are configuring AWS accounts from scratch you may be wondering, which is the best fit for me? Here we weigh the pros & cons.