
Caylent Services
Artificial Intelligence & MLOps
Apply artificial intelligence (AI) to your data to automate business processes and predict outcomes. Gain a competitive edge in your industry and make more informed decisions.
Learn how MLOps work and how you can use them to build an end-to-end Machine Learning Ops solution with Amazon SageMaker AI.
MLOps Components
Amazon SageMaker AI is a fully managed service that makes it easy for enterprises to build end-to-end production-ready machine learning pipelines without sacrificing speed, security, and accessibility. This article will propose a reference architecture based on the Amazon SageMaker AI ecosystem so you can get started right away with your own ML projects operating on the AWS platform.
MLOps, or Machine Learning Operations, is a set of practices that combines Machine Learning, DevOps, and Data Engineering to streamline the end-to-end machine learning lifecycle. It aims to design, build, and manage reproducible, testable, and evolvable ML-powered software. MLOps encompasses the entire machine learning development lifecycle, including data collection, model development, deployment, monitoring, and maintenance.
Key aspects of MLOps include:
While MLOps and DevOps share similar principles of automation, collaboration, and continuous improvement, they differ in their focus and implementation:
Both DevOps and MLOps bring a continuous iterative approach to their respective domains, with MLOps specifically tailored to the unique challenges of building, deploying, and maintaining machine learning models. DevOps, on the other hand, brings a continuous iterative approach to software engineering. It focuses on bridging the gap between development and operations teams, emphasizing collaboration, automation, and rapid delivery of high-quality software through practices like continuous integration, continuous delivery, and infrastructure as code
MLOps practices are essential in today's rapidly evolving AI landscape due to the inherent complexity of machine learning projects. Building, training, and deploying machine learning models is a multifaceted process that requires the cooperation and expertise of various team members, including data scientists, ML engineers, DevOps specialists, and business stakeholders. Without a structured approach, organizations often struggle with inconsistent processes, lack of reproducibility, and difficulties in scaling their ML initiatives. MLOps addresses these challenges by providing a framework that standardizes practices across the entire ML lifecycle. It ensures that teams work together seamlessly, from data preparation and model development to deployment and monitoring.
By implementing MLOps, organizations can achieve faster time-to-market for ML products, improve model quality through rigorous testing and validation, and enable continuous improvement of models in production. Moreover, MLOps practices enhance collaboration between different teams, fostering a culture of shared responsibility and continuous learning. This approach not only improves the efficiency of ML workflows but also helps organizations maintain compliance with regulatory requirements and industry standards, ultimately leading to more reliable and impactful AI-driven solutions.
Implementing MLOps practices offers numerous benefits to organizations including:
We will start with the simplest form of Machine Learning Operations (MLOps) and gradually add other building blocks to have a complete picture in the end. Let’s dive in!
Given a business problem or a process improvement opportunity identified and documented by the business analyst, the machine learning operation starts with exploratory data analysis “EDA” where data scientists familiarize themselves with a sample of data and apply several machine learning techniques and algorithms to find the best ML solution. They will leverage Amazon SageMaker Studio Classic which is a web-based integrated development environment (IDE) for machine learning to ingest the data, perform data analysis, process the data, and train and deploy models for making inferences using a non-production endpoint.
Inside Amazon SageMaker Studio Classic they have access to Amazon SageMaker Data Wrangler which contains over 300 built-in data transformations to quickly prepare the data without having to write any code. You can use other tools like Amazon Athena and AWS Glue to explore and prepare data. All the experiments by the data scientists will be tracked using SageMaker Experiment capability for reproducibility.

MLOps Exploration Block
Next, machine learning engineers convert the proposed solution by the data scientist to the production-ready ML code and create end-to-end machine learning workflow including data processing, feature engineering, training, model evaluation, and model creation for deployment using a variety of available hosting options. In AWS there are 4 options for orchestrating end-to-end ML workflow with Amazon SageMaker AI integration:
Amazon SageMaker Pipeline: Using Pipelines SDK a series of interconnected steps will build the entire ML pipeline that is defined using a directed acyclic graph (DAG).
Amazon Managed Workflow for Apache Airflow (MWAA): Using Airflow SageMaker operators or Airflow PythonOperator end-to-end ML pipeline can be configured, scheduled, and monitored.
AWS Step Function Workflow: Integration between AWS SageMaker AI and AWS Step Functions through the AWS Step Function Data Science SDK allows one to easily create multi-step machine learning workflows.
Kubeflow Orchestration: Amazon SageMaker AI components for Kubeflow pipelines allows you to submit SageMaker AI processing, training, HPO jobs, and deploy the model directly from the Kubeflow pipeline workflow.
As part of the model evaluation/test step, AWS Step Function can run a comprehensive suite of ML-related tests. Additionally, Amazon SageMaker Feature Store is used to store, share, and manage features for machine learning (ML) models during training (offline storage) and inference (online storage). Finally, SageMaker AI ML Lineage tracking is enabled to track data, and model lineage metadata which is crucial for ML workflow reproducibility, model governance, and audit standards.
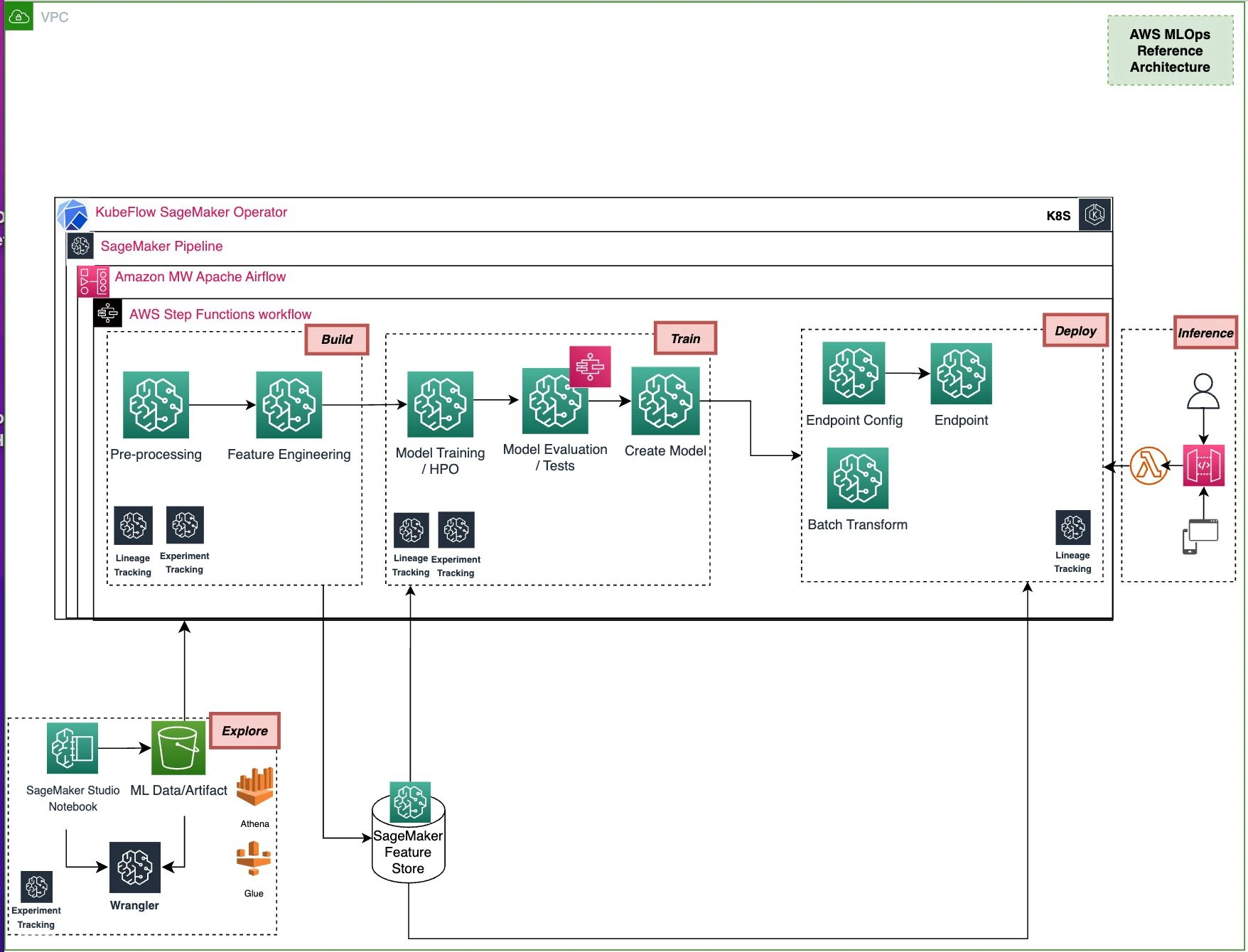
MLOps ML Workflow Block
After implementing the first two blocks, we already have a fully functioning ML workflow and endpoint that users or applications can call to consume the ML prediction. To take this to the next level and to eliminate manual work as a result of making any update to the code or infrastructure, an MLOps engineer will build up the Continuous Integration (CI) block.
This enables data scientists or ML engineers to regularly merge their changes into AWS CodeCommit, after which automated builds and tests are run using AWS CodeBuild. This includes building any custom ML image based on the latest container hosted on Amazon ECR which will be referenced by the ML workflow consequently.

MLOps Continuous Integration Block
Not only do we want to build and test our ML application each time we push a code change to AWS CodeCommit, but also, we want to deploy the ML application in production continuously. In the Continuous Deployment (CD) block the proposed solution is extended to decouple the model training workflow from the model deployment section. This provides an opportunity to update the model configuration and infrastructure without affecting the training workflow.
To manage model versions, model metadata, and automate the model deployment with CI/CD, the Amazon SageMaker Model Registry is used. Here, the manual approver (e.g. the senior data scientist), will approve the model which triggers a new automated deployment through AWS CodePipeline, AWS CodeBuild, and AWS CloudFormation. The Automatic Rollback feature of AWS CloudFormation is key here, in case anything goes wrong during the deployment. Amazon SageMaker AI elastic endpoint autoscaling is also configured to handle changes in the inference workload.

MLOps Continuous Deployment Block
When building machine learning models, we assume that the data used when training the model is similar to the data used when making predictions. Therefore, any drift in data distribution or model performance on the new inference data will result in data scientists needing to revisit the features or retrain the model to reflect the most recent changes.
The Continuous Training (CT) block continuously monitors the data and model quality to detect any bias or drift and inform a timely remediation . This will be achieved by enabling Amazon SageMaker Model Monitor in the inference endpoint configuration, creating baseline jobs during data prep and training along with Amazon SageMaker Clarify feature and Amazon CloudWatch event to automatically monitor for any drift, trigger re-training, and notify the relevant parties.

MLOps Continuous Training Block
To make our MLOps architecture secure, some important security and governance requirements are recommended. This includes:
In this blog post, we have proposed a reference architecture to build an end-to-end secure, scalable, repeatable, and reproducible MLOps solution to process data, train, create & update models, as well as deploy and monitor deployed model using Amazon SageMaker AI features with CI/CD/CT concepts incorporated.
If your team needs expert assistance to deploy Machine Learning models on AWS at scale, consider engaging with Caylent to craft a custom roadmap with our collaborative MLOps Strategy Assessment and/or realize your vision through our MLOps pods.

Ali Arabi is a Senior Machine Learning Architect at Caylent with extensive experience in solving business problems by building and operationalizing end-to-end cloud-based Machine Learning and Deep Learning solutions and pipelines using Amazon SageMaker AI. He holds an MBA and MSc Data Science & Analytics degree and is AWS Certified Machine Learning professional.
View Ali's articles

Explore the pros and cons of on-premise hosting vs cloud hosting for machine learning.

From notebooks to frictionless production: learn how to make your ML models update themselves every week (or earlier). Complete an MLOps + DevOps integration on AWS with practical architecture, detailed steps, and a real case in which a Startup transformed its entire process.
