

Caylent Catalysts™
Generative AI Knowledge Base
Learn how to improve customer experience and with custom chatbots powered by generative AI.

File Processing Speed

IdenX is an analytics-as-a-service company that uses proprietary machine learning and artificial intelligence technology as well as their industry-specific expertise to provide its clients with customized, data-driven insights across a wide range of organizational challenges, including talent acquisition, logistics, mergers and acquisitions, population trends, market projections, force protection, and insider threats. IdenX aims to provide its clients with comprehensive, transparent data analytics that allow them to make strategic decisions confidently.

IdenX’s research has traditionally involved time and resource-intensive processes, including some largely repeated tasks, from querying thousands of files and datasets, converting text into SQL, data quality assessment, and analysis. In discussions with AWS, IdenX gained interest in utilizing a Generative AI-powered application that could act as a force multiplier, abstracting away undifferentiated time-consuming tasks. They were also interested in being able to lower the technical barrier to entry for their operational and analytics team members, democratizing access to actionable data across their organization.
Caylent and IdenX engaged to develop a model that assesses files based on the richness of relevant biographical information.

Dr. Andrew Sharp
CTO
IdenX’s files vary in size, encoding, formats (such as CSV, SQL Dumps, TXT, and RTF) and languages. In addition to employing a Large Language Model (LLM) to identify metadata (e.g., delimiter, encoding, and header), Caylent would deploy a pipeline for data processing. The ultimate goal was to identify entities irrespective of language and calculate the density quotient to determine whether a file is worth parsing.
After testing Amazon SageMaker AI, Amazon Textract and AWS Comprehend, the teams decided to pursue a solution with Amazon Bedrock. Amazon Bedrock’s GenAI capabilities enable IdenX to combine a natural language interface for querying, with the capability to generate metrics representing the density of relevant information for files in IdenX’s database. To achieve this, Caylent implemented scripts designed to extract metadata from the files and measure the density.
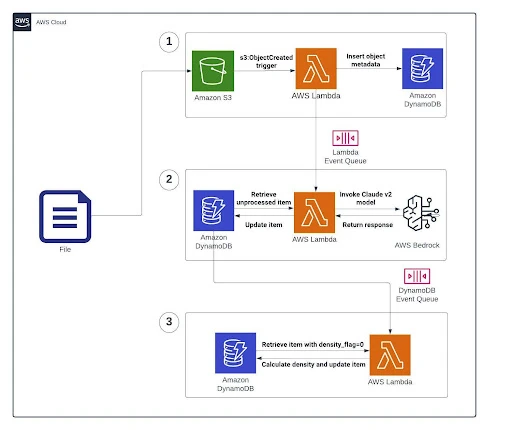
Upon the upload of a new file to the S3 bucket (triggered by the s3:ObjectCreated event), a Lambda function is invoked. This function populates a DynamoDB table (profiling) with metadata, serving as a support table for subsequent processing.
A second Lambda, triggered by DynamoDB, retrieves unprocessed items. This Lambda then invokes the Claude 3 Haiku or Sonnet models, captures the response from Bedrock, and updates the DynamoDB table with the information obtained.
A final Lambda identifies items with density_flag=0, indicating files yet to go through density calculation. This Lambda computes the density, updating the DynamoDB table accordingly.
A workflow of this operation can be seen in our infrastructure diagram, detailed below:
1. Lambda function ‘s3-bedrock-dynamo’ invokes the DynamoDB table ‘profiling’ for all items with the attribute ‘processed’ equal to False.
2. Utilizing Prompt Engineering in Bedrock, we tailored responses to extract specific information. This step makes two Bedrock calls:
a. We query Bedrock to find the delimiter in the data by prompting the first line of the CSV file.
b. Then, we query Bedrock with the next five lines from the CSV file to get the following information:
3. Lambda function ‘Density’ is triggered by the DynamoDB event after it is updated with the entities from the Bedrock responses. It retrieves all items from the ‘profiling’ table with attribute ‘processed’ equal to True and ‘density_flag’ equal to 0.
4. Then, the Lambda function will get a byte position (random value) and get a sample of ‘n’ lines from that position. With ‘n’ depending on the batch size limit.
5. The density calculation function is then run, with the response saved into the table. Density_flag is set to 1.
CSV files are processed regardless if the extension is TXT or TSV. Although a limited number of lines were utilized, all the columns had to be passed to Bedrock, increasing the number of tokens and influencing the processing time and potential costs. In other words, the more columns a file has, the greater the expected processing time and costs.
To optimize costs, only a few lines from the file are used in the Prompt, as described above.
The number of lines in a file are estimated utilizing a rule of three based on the sample size, number of lines, and total file size. This strategic approach allowed us to do initial development within the free tiers of Bedrock and Lambda, ensuring cost-effectiveness.
An on-demand pricing model for Bedrock was used to allow the client to use foundation models on a pay-as-you-go basis, while provisioned throughput is designed for large, consistent inference workloads.
Prior to IdenX’s Generative AI application, a tremendous time and resource investment was required for querying files to determine fit. Manual efforts would limit their pace to about 500 files per resource per day. Scaling these capabilities would prove to be very costly and inefficient in the long term.
With an Amazon Bedrock powered deployment, IdenX can query thousands of files instantly and maximize the efficiency of their time and resources. The solution handles files of varying sizes, delimiters, languages, and the presence of column headers in a time and resource-efficient manner. Their experts can spend a significantly larger chunk of their time analyzing data and providing their customers with insights, improving their employee and customer experiences.

Caylent Catalysts™
Learn how to improve customer experience and with custom chatbots powered by generative AI.
Caylent Catalysts™
Accelerate your generative AI initiatives with ideation sessions for use case prioritization, foundation model selection, and an assessment of your data landscape and organizational readiness.



